The Stack and The Heap in Rust
The stack and the heap are constructs that help us understand how memory management works in Rust. Memory management in Rust is closely tied to ownership.
If you are used to working with low level languages (like Python), then you may not be familiar with concepts related to memory management. Because of Rust’s focus on memory safety, it is necessary to have at least a basic grasp of these concepts.
Although they may seem complicated at first, the stack and the heap are actually pretty easy to understand. This article will start with a review of basic memory management concepts and then move on to the details of how the stack and heap work in Rust.
Memory Management Basics
In order to understand how the stack and heap work, we need to have a high level overview of computer memory.
Memory works by storing data at address locations. The address identifies where the data is stored in memory. For example, if your computer has 1GB of RAM, then it has 1,073,741,824 places to store information. The available addresses range from an address of 0 all the way through 1,073,741,823.
| Memory Address | Data |
| 1,073,741,823 | 42 |
| … | |
| 3 | t |
| 2 | s |
| 1 | u |
| 0 | R |
Now that we have a basic understanding of how memory works, let’s see how this is applied to the stack and the heap.
The Stack
In Rust, the stack is a Last In, First Out (LIFO) construct used to store and retrieve data very quickly. Think of a stack of books:

Each book contains information (data) and books can be added to or removed from the top of the stack. order to get a book from the middle of the stack, you have to remove the books above it.
Similarly, in Rust the stack consists of data located at memory addresses:

The stack is very accessible and items can be pushed onto the stack or popped off it quickly.
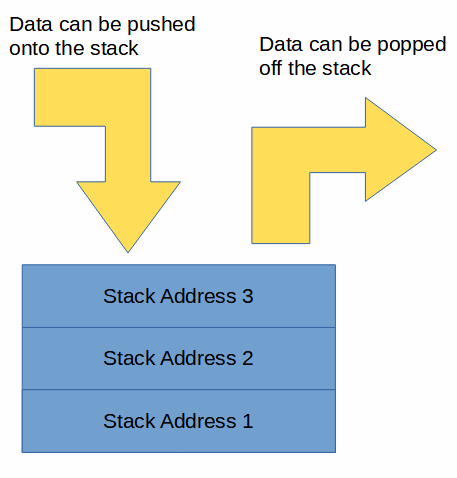
This makes using the stack very fast. However you wouldn’t want to keep all of your books in a stack! It’s best for a small number of books that you want to access quickly.
How the Stack Works in Rust
Each address in the stack has to hold data that corresponds to a variable binding in the code. In the following example, there are two variables declared, ‘x’ and ‘y’:
fn main() {
let x = 42;
let y = 8;
}Rust stack allocates by default. This means that values are stored on the stack (rather than the heap) by default.
A ‘stack frame’ is formed to store the data. We can think of the stack frame for this example like this:
| Address | Name | Value |
| 1 | y | 8 |
| 0 | x | 42 |
The variable ‘x’ was declared first, so it went onto the stack first. Then when the variable ‘y’ was declared, it was pushed onto the stack on top of ‘x’.
Limitations of the Stack
When these variables go out of scope, the memory will be deallocated. This is great for speed and safety. However it also means that we are very limited in what we can do. In order for the stack to function, the compiler needs to know the size of the data that it needs to allocate. This means that it can only be used for primitive types.
Moreover, we can’t use variables outside their local scope or pass data from one function to another using the stack alone.
That’s where the heap comes in.
The Heap
The heap is a large data storage area that is used to store data whose size is unknown at compile time, or whose size might change.
If the stack is like a stack of books then the heap is more like a bookshelf.

A bookshelf can store a huge number of books, but it can also take longer to find the book you want as well as find a place big enough for a new book.
Let’s say we get a new book. We need to find enough space on the shelf for it. Later when we want to retrieve it, we either need to remember where it is or use some type of indexing system to tell us where to look for it.
Memory management on the heap is similar. Visually, the heap is often represented with blocks of data stored next to each other:

Like slotting a book into a bookshelf, data can only be stored on the heap where there is room for it.
Now that we have a general idea of what the heap is, let’s dive into how it actually works.
How the Heap Works in Rust
The heap is less organized than the stack. Instead of pushing data to the top of a stack, the memory allocator has to search the heap for enough free memory space to store the required data.
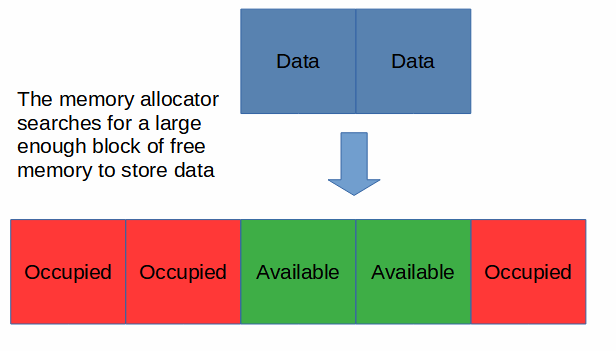
The data gets stored on the heap, but because it isn’t organized we still need a way to track where the data was stored so that it can be retrieved. After the data is stored on the heap, a pointer to the memory address (i.e. the location in memory) of the data gets pushed to the top of the stack.
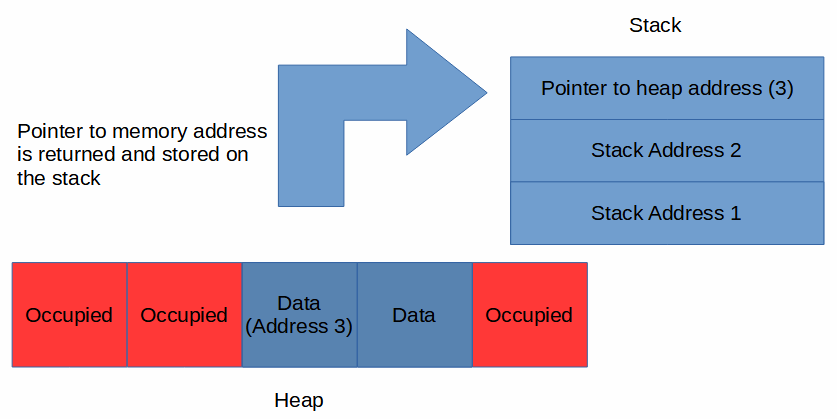
When the data is retrieved, the compiler follows the pointer on the stack to the memory address in the heap.
Note that this is a simplified example that omits some details for clarity. In particular, the addresses referenced are trivial and the stack stores more than just the pointer. For example, a string object stores 3 things on the stack: the pointer, the length of the string, and the capacity.
Why does the heap work like this? In a bookshelf we would probably sort the books to keep things organized. But so much information is being moved around in memory that continually reorganizing the heap isn’t practical.
Instead, information gets stored wherever it can fit and a pointer to the location on the heap gets stored on the stack. That way, we get most of the speed benefits of the stack while still being able to use the heap to store and retrieve lots of data at once.
The bookshelf analogy is useful here if we assume a large collection of books, like a library. Books can be sorted in many different ways (alphabetically, by type, by language) and it isn’t clear what the best way is. That’s why libraries adopt classification systems like the Dewey Decimal System. A number is assigned to every new book, and the library is organized based on these numbers (similar to memory addresses). When you want to grab a book, you would first identify the number (analogous to a pointer) from the index (analogous to the stack) and then use the number to find the book’s location in the library (analogous to the heap).
The Stack vs. The Heap
Now that we understand how the stack and heap work, we can see why each has a specific use case:
- Pushing values onto the stack is much faster than allocating memory on the heap. This is because using the heap requires several operations:
- A block of free memory with sufficient space is identified.
- The data gets stored on the heap.
- A pointer to the location (address) of the data gets pushed onto the stack.
- Popping values off the stack is much faster than retrieving data from the heap. To get the data from the heap:
- The pointer is retrieved by popping it off the stack.
- The pointer is followed to the location of the data on the heap.
- The data is retrieved from the heap.